Hao Qi Research Group within the Autonomous Driving Center of the Research Institute of Trustworthy Autonomous Systems (RITAS), Southern University of Science and Technology (SUSTech), in collaboration with the University of Macau, and Shenzhen DeepRoute.AI Company, has published a research article titled “TSceneJAL: Joint Active Learning of Traffic Scenes for 3D Object Detection” in the prestigious journal IEEE Transactions on Intelligent Transportation Systems (T-ITS).
In autonomous driving, 3D object detection relies on high-quality, precisely annotated datasets. However, the annotation process is labor-intensive and costly. Active learning presents a promising solution by selecting a small but informative subset of unlabeled data for annotation, reducing costs while maintaining model performance. Despite this, traditional active learning methods often struggle with issues such as class imbalance, scene redundancy, and insufficient complexity in autonomous driving datasets.
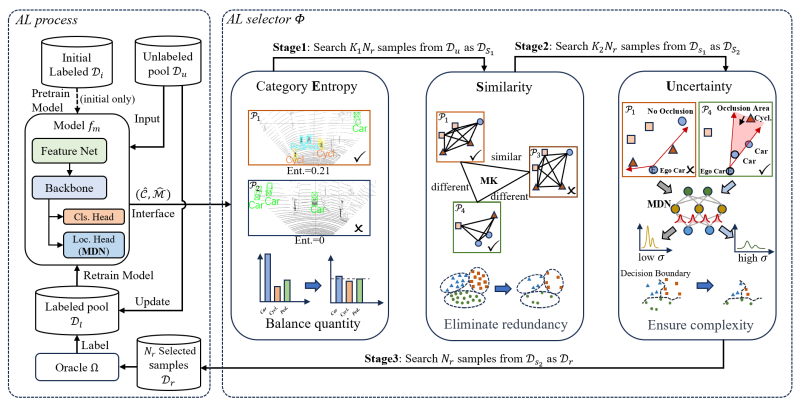
Fig. 1 An illustration of our proposed TSceneJAL framework
To tackle these challenges, the research team proposed an innovative three-stage joint active learning framework called TSceneJAL, as shown in Fig.1. This framework dynamically optimizes balance, diversity, and complexity in data selection to achieve the goal of training an optimal model with minimal annotated data. 1)Class Entropy Sampling: Selects scenes with multiple object classes to mitigate class imbalance. 2)Scene Graph Similarity Measurement: Traffic scenes are modeled as directed graphs (with nodes representing object classes and edges representing spatial distances). Utilizes the MarginalizeKernel algorithm to measure graph similarity and eliminate redundant scenes. 3)Uncertainty Sampling using a Mixture Density Network: A mixture Gaussian distribution network is incorporated into the detection model to simultaneously estimate data noise uncertainty (aleatoric uncertainty) and model epistemic uncertainty, prioritizing the selection of complex scenes with high uncertainty.
Experimental results across multiple datasets demonstrate that TSceneJAL achieves state-of-the-art performance in active learning for 3D object detection, as shown in Fig.2. Compared to existing methods, the framework improves several key metrics, including 3D mean average precision (3D-mAP) by up to 11%; annotating only 32% of the KITTI dataset is sufficient to achieve 92% of the detection performance obtained with the full dataset; and detection accuracy for classes such as pedestrians and cyclists is improved by 10–15%, effectively mitigating the class imbalance issue.
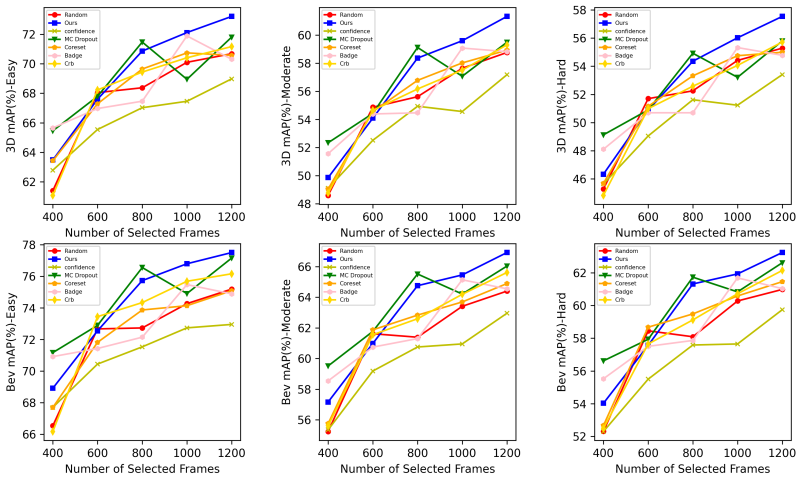
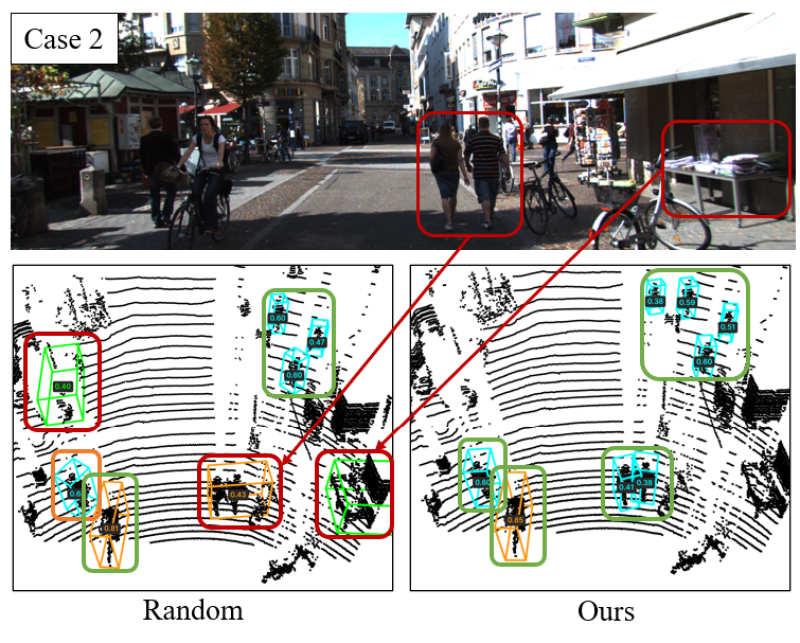
Fig. 2 Experiment results of different AL methods with an increasing number of scenes on the KITTI
Research Assistant Professor Meiying Zhang and Professor Qi Hao are the co-corresponding authors, and Chenyang Lei, a master's student in the Department of Computer Science and Technology, SUSTech, is the first author.
T-ITS is one of the most influential international top-tier journals in the field of intelligent transportation systems, dedicated to pioneering advancements in intelligent transportation theories, technologies, and applied breakthroughs.



